
Building a Production-Ready Data Pipeline on AWS: A Practical Guide
How we built a scalable clickstream analytics pipeline that processes 500GB/day while cutting costs by 70%

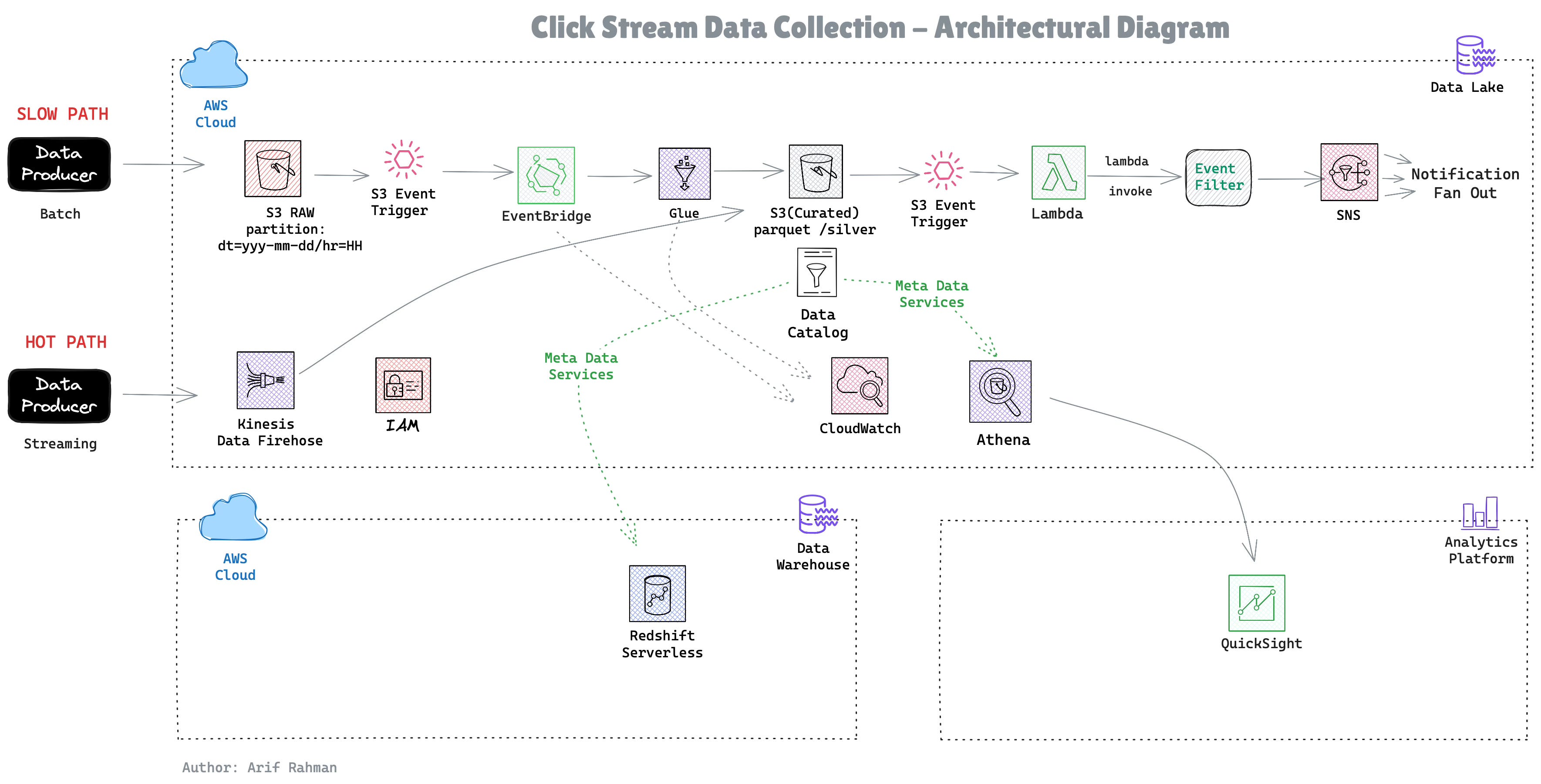
Architectural Diagram
The Challenge
You’re a data engineer at a growing e-commerce company. Every hour, your web application generates millions of clickstream events—page views, add-to-carts, purchases. These land as JSON files in S3, and your business teams are demanding:
Real-time alerts when high-value purchases occur
Fast analytics to power dashboards and reports
Cost efficiency (because cloud bills are no joke)
Scalability to handle 10x growth
Key Highlights of this Architecture
Part 1: S3 partitioning strategy showing 95% cost reduction
Part 2: Star schema justification with performance comparisons
Part 3: Hybrid analytics approach (hot/warm/cold) saving $7,698/month
Part 4: Event-driven architecture explaining why NOT to use Kinesis
Part 5: Cost optimization playbook: $10K → $3K/month
Part 6: Honest “what we’d do differently” section
Part 7: Real query optimization example (37x speedup)
Part 8: Security and GDPR compliance
Part 9: Monitoring that actually matters
Part 10: Infrastructure as Code with Terraform
High level code snippets
Contact US